Preparing Your Enteprise for Agentic AI
To unlock the potential of agents, organizations have some housekeeping to do
By Andrew Wig
Agentic AI is starting to get real, and the pressure is on.
As the technology evolves, it will be increasingly expected to yield real return on investment, meaning that mere proofs of concept (POC) are no longer the measure of success. More and more, success is instead defined by live deployment.
“That's a shift from last year, where only POCs were being targeted as a success factor,” says Jignesh Desai, a go-to-market leader at AWS who works to educate customers about agentic AI.
As enterprises seek to innovate by deploying teams of tireless, autonomous digital workers, they have a lot to consider as they make this fundamental change to the way they get things done.
Empower Your Future with COMMON
- ‹ prev
- next ›
- 1
- 2
- 3
- 4
- 5
- 6
- 7
The Data Comes First
First, assess the data. “That is the foundational thing that we tell all our customers,” Desai says.
Before the data can be used by an agent, it may need to be transformed. For instance: “Sometimes it's harder to get an agent to connect to a VSAM file in the mainframe. It's easier for you to get that extracted into a modern data source in AWS and then have the agent use that,” says Paulo Pereira, worldwide tech leader for mainframe modernization at AWS.
Data residence is also critical. As enterprises get started on their agentic AI journeys, they are typically dealing with pools of data that largely remain siloed, providing a stumbling block for the data-hungry agents spread across the organization.
Over the past 10 years, the popular solution has been the data lake, but the problem with data lakes is “you're creating a single point of failure, because all the data is sitting in one place, and then there is a single team which is getting slammed by everyone,” says Saurabh Shrivastava, global head of specialist solutions architecture at AWS.
As an alternative, he suggests the data mesh, a multiple parallel processing approach where each department within an organization takes ownership of their data and exposes it as a “product” to be consumed by other departments, managed by a query layer over the top.
The Data Mesh
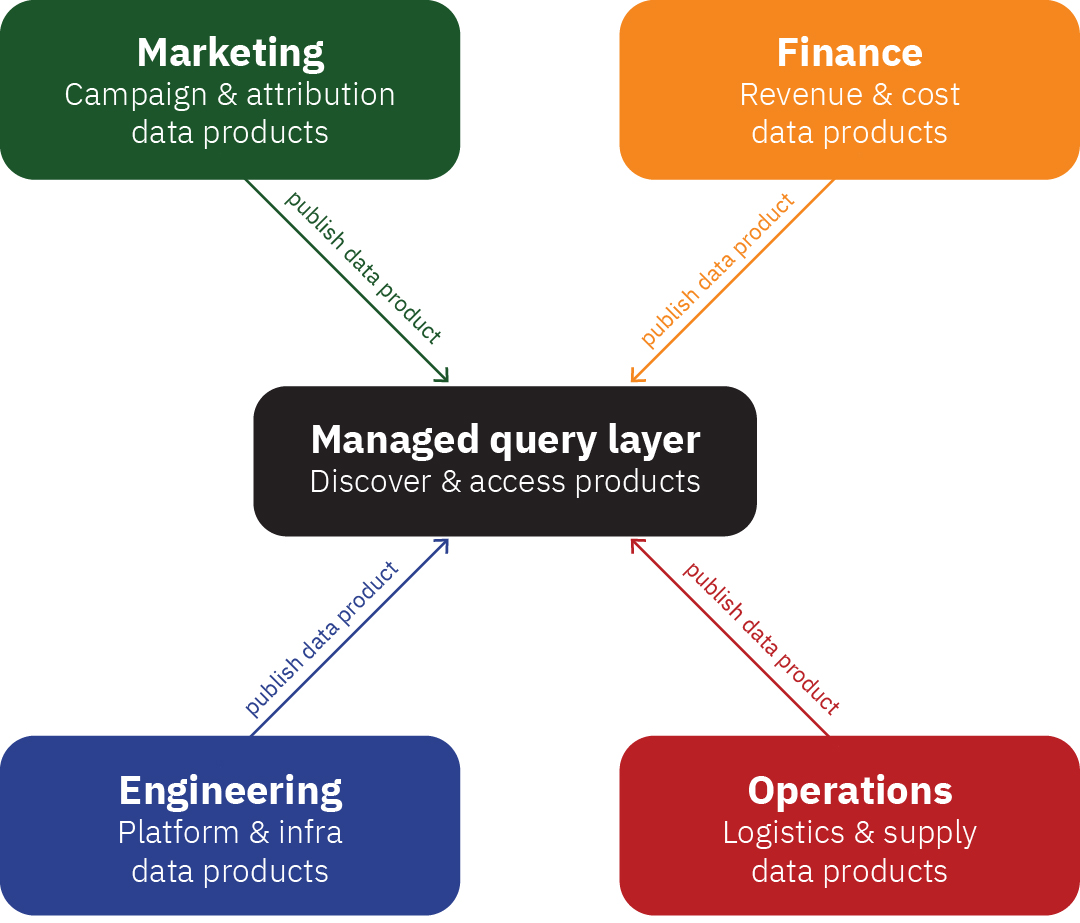
Context Is Key
Once the agents are able to access the data efficiently, it’s important to make sure they have enough information for the task at hand. Supplying just the core data set is often not enough.
Like humans, agents need context to understand the data they’re looking at, and Livingston notes that even seemingly simple data sets can bedevil an agent that has no additional information. That’s why, she adds, IBM has teams writing documents so that its internal agents can understand the data they’re working with.
A package of such contextual information, for instance, might include an example financial report and a definition file. And yes, Livingston says, maybe those documents will be built by an agent.
“We're at a point where we're just starting to try to do that,” she says. “But again, we have humans in the loop that are actually cleaning up those description documents and making sure that they are right.”
Supplying the right kind of data is part of an iterative development process that unfolds as teams build and test agents through trial and error. This process also helps clean that data—“The data itself has to be super clean,” Livingston says.
Teams help ensure that by investigating when an agent provides errant output and then checking the data to see what went askew. “That's really where data teams are spending a lot of time getting prepared for their data to be used inside of agents,” Livingston says.
Security and Compliance the ‘Major Hurdle’
While data itself might be the first thing to consider in any agentic AI project, security and compliance is “the major hurdle,” according to Shrivastava. In this way, a deterministic approach (security) is required to keep a probabilistic one (agentic and generative AI) within the guardrails.
Three-Pillar Security

Getting the Humans on Board
One condition that experts say should always be present at certain points in agentic workflows is the human. In fact, the assurance that humans will continue to be present in the process can help promote buy-in, another critical factor in the success of an AI deployment.
AWS’s customers are no longer only looking for 100% automation, and are instead leaning on humans to intervene as necessary, Pereira says. “They're now looking into increasing the efficiency of their journey overall, and they're okay with results that require human review, as long as they can have the SMEs (subject matter experts) to correct that,” he says.
To further engage staff in AI projects—and demonstrate those projects' value—there are three organizational layers to consider, Shrivastava notes:
↪ The Boardroom
The Boardroom
↪ Day-to-Day Operations*
Day-to-Day Operations*

↪ The Builders
The Builders
For those in day-to-day operations who are most skeptical of agentic AI, one important factor will be compliance and security, Shrivastava notes. These technologists will also be the ones facing the pressure to bring the microservices architecture they are familiar with into an alien agentic architecture.
It won’t be alien for long, in Shrivastava’s estimation. He expects agentic architecture to become the norm in the next 12-18 months. “It'll become business as usual where instead of microservice, everyone will talk about the agentic distributed architecture,” Shrivastava says.
One Thing at a Time
Bridging silos, transforming data and securing AI agents may seem like a daunting project for any enterprise, but it doesn’t all have to happen in one go. Enterprises can start by seeking small wins, Shrivastava notes.